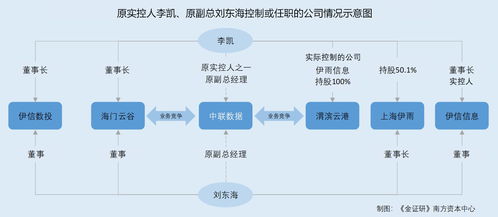
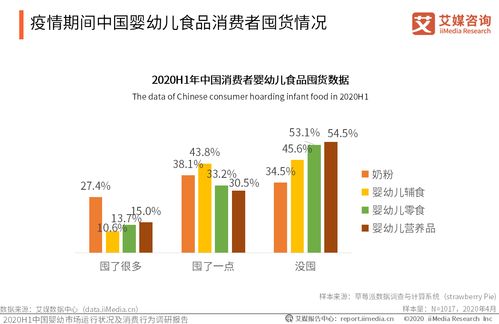
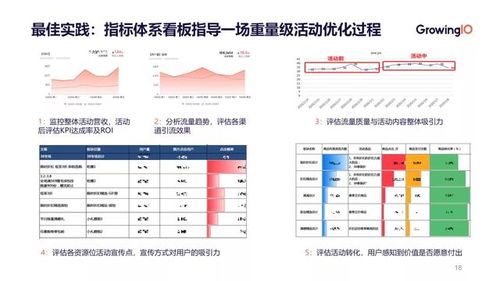
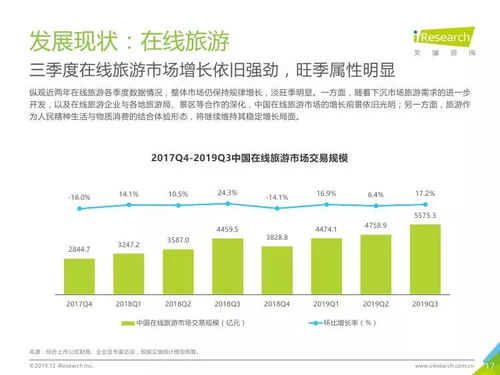
大數據工程師 崗位要求、成長路徑與在線數據處理業務解析
一、大數據技術崗位的核心要求
大數據領域崗位多樣,主要包括大數據開發工程師、大數據平臺工程師、數據分析師、數據科學家等。雖然側重點不同,但普遍要求以下核心能力:
- 扎實的技術棧基礎:
- 編程語言:精通Java、Scala、Python(尤其是PySpark生態)至少一種,SQL是必備技能。
- 大數據生態框架:深入理解并掌握Hadoop(HDFS, YARN)、Spark(Core, SQL, Streaming)、Flink等核心計算與處理框架。對Hive、HBase、Kafka、ZooKeeper等組件的原理和應用有豐富經驗。
- 數據存儲與數倉:熟悉關系型數據庫、NoSQL數據庫(如Redis、MongoDB),并了解數據倉庫建模理論(如維度建模)和OLAP技術(如ClickHouse、Doris)。
- 系統工程與平臺能力:
- 能夠進行集群規劃、部署、監控、調優和故障排查,保障平臺的穩定與高效。
- 熟悉Linux操作系統和Shell腳本,了解容器化技術(如Docker、Kubernetes)。
- 數據處理與開發能力:
- 具備從數據采集、清洗、存儲、計算到可視化輸出的全流程開發和架構設計能力。
- 能夠編寫高效、穩定、可維護的ETL/ELT任務代碼,并具備良好的性能優化意識。
- 業務理解與軟技能:
- 能夠將模糊的業務需求轉化為清晰的技術方案和數據產品。
- 具備良好的溝通能力、團隊協作精神和強烈的責任心。
二、從入門到資深:大數據工程師的成長路徑
成為一名資深的大數據工程師,通常需要經歷以下階段和持續努力:
- 夯實基礎階段(0-2年):
- 目標:掌握核心組件的使用和基礎開發。
- 行動:深入學習一門編程語言和SQL,在本地或云環境搭建Hadoop/Spark集群,完成簡單的數據處理項目。理解MapReduce、Spark RDD等基礎編程模型。
- 能力深化階段(2-5年):
- 目標:參與復雜項目,具備子系統或模塊的設計能力。
- 行動:深入參與企業級數據平臺建設,負責關鍵數據管道開發。深入研究框架源碼(如Spark執行計劃、Flink狀態管理)、JVM及GC調優、資源調度優化。開始關注數據質量、數據治理和任務調度(如DolphinScheduler, Airflow)。
- 專家/架構階段(5年以上):
- 目標:主導技術方向,進行系統架構設計和團隊能力建設。
- 行動:
- 技術深度:能針對業務場景和技術瓶頸,進行框架選型、定制化改造甚至自研組件。
- 架構廣度:設計高可用、高并發、可擴展的數據平臺架構,平衡成本與性能。
- 業務影響力:推動數據驅動決策,通過數據架構賦能業務創新(如實時推薦、風控模型)。
- 方法論沉淀:建立團隊開發規范、數據治理體系和技術演進路線圖。
持續學習是貫穿始終的關鍵,需緊跟流批一體、湖倉一體、DataOps等前沿趨勢。
三、在線數據處理與交易處理業務(EDI & OLTP)中的大數據實踐
在線數據處理(通常指聯機分析處理OLAP)與在線交易處理(OLTP)是大數據技術賦能業務的兩大核心場景。
- 場景特點與技術挑戰:
- OLAP(在線數據分析):側重于復雜查詢和數據分析,數據量巨大,但更新頻率較低。挑戰在于查詢速度和并發能力。常用技術包括預計算(物化視圖)、列式存儲(Parquet/ORC)、MPP架構數據庫(ClickHouse)以及Spark SQL等。
- OLTP(在線交易處理):側重于高并發、低延遲的短小事務處理(如訂單支付、庫存更新),要求極強的數據一致性和可用性。傳統關系數據庫是主力,但大數據技術如Kafka可用于解耦和流量削峰,Flink用于實時對賬和風控。
- 大數據技術的融合應用:
- Lambda/Kappa架構:經典的大數據架構,兼顧實時(Speed Layer, 使用Flink/Spark Streaming)與批處理(Batch Layer, 使用Hive/Spark)需求,為業務提供從實時監控到歷史深度分析的全方位數據服務。
- 實時數倉與數據湖:利用Flink CDC等技術實時捕獲數據庫變更日志,構建實時數據管道,將OLTP系統的數據實時同步到數據湖(如Iceberg/Hudi)或數倉中,支持秒級延遲的OLAP查詢,實現“交易即分析”。
- 服務化與API化:將處理好的數據通過數據服務層(如GraphQL、Restful API)高效、安全地暴露給前端交易系統或其他應用,形成數據閉環。
而言,成為一名資深大數據工程師,不僅需要構建深厚的技術金字塔,更需深刻理解像在線數據處理與交易處理這樣的核心業務場景,并能用大數據技術架起數據與業務價值之間的橋梁,驅動企業智能化升級。
如若轉載,請注明出處:http://www.bstoy.com.cn/product/61.html
更新時間:2026-01-24 11:40:13